
Mac Speed Comparison: M2 Ultra vs M3 Ultra using KoboldCpp
tl;dr: Running ggufs in Koboldcpp, the M3 is marginally... slower? Slightly faster prompt processing, but slower prompt writing across all models. I added a comparison Llama.cpp run at the bottom; same speed as Kobold, give or take.
Setup:
- Inference engine: Koboldcpp 1.85.1
- Text: Same text on ALL models. Token size differences are due to tokenizer differences
- Temp: 0.01; all other samplers disabled
Computers:
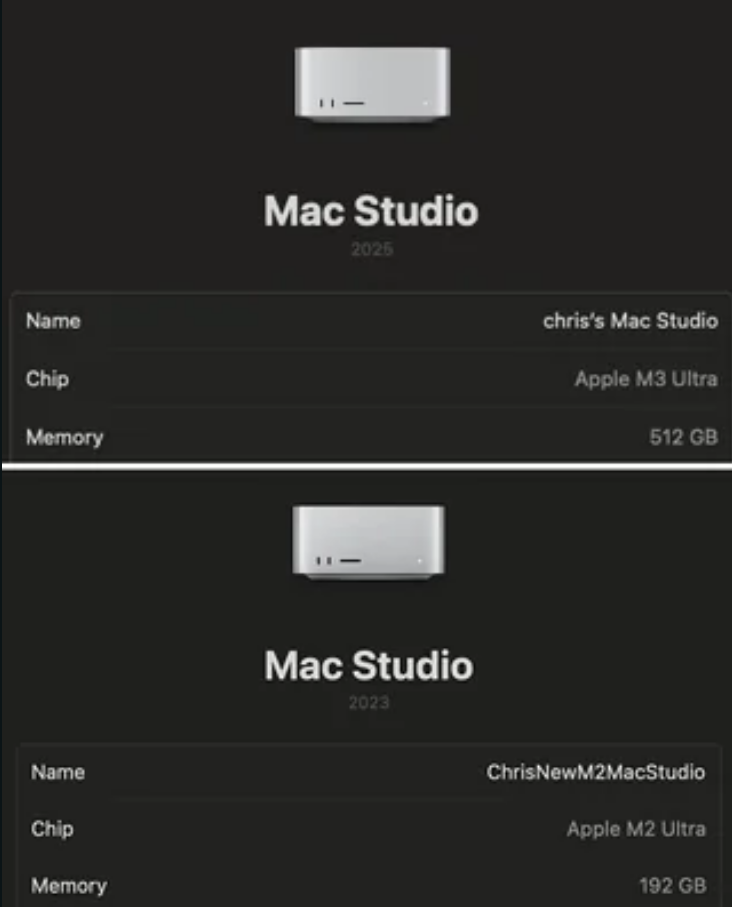
- M3 Ultra:
- 512GB RAM
- 80 GPU Cores
- M2 Ultra:
- 192GB RAM
- 76 GPU Cores
Notes:
- Qwen2.5 Coder and Llama 3.1 8b are more sensitive to temp than Llama 3.3 70b
- All inference was first prompt after model load
- All models are q8, as on Mac q8 is the fastest gguf quant (see my previous posts on Mac speeds)
Llama 3.1 8b q8
M2 Ultra:
CtxLimit:12433/32768,
Amt:386/4000, Init:0.02s,
Process:13.56s (1.1ms/T = 888.55T/s),
Generate:14.41s (37.3ms/T = 26.79T/s),
Total:27.96s (13.80T/s)
M3 Ultra:
CtxLimit:12408/32768,
Amt:361/4000, Init:0.01s,
Process:12.05s (1.0ms/T = 999.75T/s),
Generate:13.62s (37.7ms/T = 26.50T/s),
Total:25.67s (14.06T/s)
Mistral Small 24b q8
M2 Ultra:
CtxLimit:13300/32768,
Amt:661/4000, Init:0.07s,
Process:34.86s (2.8ms/T = 362.50T/s),
Generate:45.43s (68.7ms/T = 14.55T/s),
Total:80.29s (8.23T/s)
M3 Ultra:
CtxLimit:13300/32768,
Amt:661/4000, Init:0.04s,
Process:31.97s (2.5ms/T = 395.28T/s),
Generate:46.27s (70.0ms/T = 14.29T/s),
Total:78.24s (8.45T/s)
Qwen2.5 32b Coder q8 with 1.5b speculative decoding
M2 Ultra:
CtxLimit:13215/32768,
Amt:473/4000, Init:0.06s,
Process:59.38s (4.7ms/T = 214.59T/s),
Generate:34.70s (73.4ms/T = 13.63T/s),
Total:94.08s (5.03T/s)
M3 Ultra:
CtxLimit:13271/32768,
Amt:529/4000, Init:0.05s,
Process:52.97s (4.2ms/T = 240.56T/s),
Generate:43.58s (82.4ms/T = 12.14T/s),
Total:96.55s (5.48T/s)
Qwen2.5 32b Coder q8 WITHOUT speculative decoding
M2 Ultra:
CtxLimit:13315/32768,
Amt:573/4000, Init:0.07s,
Process:53.44s (4.2ms/T = 238.42T/s),
Generate:64.77s (113.0ms/T = 8.85T/s),
Total:118.21s (4.85T/s)
M3 Ultra:
CtxLimit:13285/32768,
Amt:543/4000, Init:0.04s,
Process:49.35s (3.9ms/T = 258.22T/s),
Generate:62.51s (115.1ms/T = 8.69T/s),
Total:111.85s (4.85T/s)
Llama 3.3 70b q8 with 3b speculative decoding
M2 Ultra:
CtxLimit:12519/32768,
Amt:472/4000, Init:0.04s,
Process:116.18s (9.6ms/T = 103.69T/s),
Generate:54.99s (116.5ms/T = 8.58T/s),
Total:171.18s (2.76T/s)
M3 Ultra:
CtxLimit:12519/32768,
Amt:472/4000, Init:0.02s,
Process:103.12s (8.6ms/T = 116.77T/s),
Generate:63.74s (135.0ms/T = 7.40T/s),
Total:166.86s (2.83T/s)
Llama 3.3 70b q8 WITHOUT speculative decoding
M2 Ultra:
CtxLimit:12519/32768,
Amt:472/4000, Init:0.03s,
Process:104.74s (8.7ms/T = 115.01T/s),
Generate:98.15s (207.9ms/T = 4.81T/s),
Total:202.89s (2.33T/s)
M3 Ultra:
CtxLimit:12519/32768,
Amt:472/4000, Init:0.01s,
Process:96.67s (8.0ms/T = 124.62T/s),
Generate:103.09s (218.4ms/T = 4.58T/s),
Total:199.76s (2.36T/s)
Llama.cpp Server Comparison Run :: Llama 3.3 70b q8 WITHOUT Speculative Decoding
M2 Ultra
prompt eval time = 105195.24 ms / 12051 tokens (
8.73 ms per token, 114.56 tokens per second)
eval time = 78102.11 ms / 377 tokens (
207.17 ms per token, 4.83 tokens per second)
total time = 183297.35 ms / 12428 tokens
M3 Ultra
prompt eval time = 96696.48 ms / 12051 tokens (
8.02 ms per token, 124.63 tokens per second)
eval time = 82026.89 ms / 377 tokens (
217.58 ms per token, 4.60 tokens per second)
total time = 178723.36 ms / 12428 tokens