
RAG Really Is More of a Software Problem Than An AI Problem
RAG is really 90% a software development problem, 10% an AI problem. People overcomplicate it on the AI side a lot, but it's a $5 term for a $0.05 concept: give the LLM the answer before it responds to you.
At its face, that's simple enough- but too many folks take that literally, and just look for the biggest context models they can find. A lot of times that's not really what you want, though.
Say you have 300,000+ tokens of data, and an LLM that can handle 1M tokens. But then you look at context benchmarks, like FictionBench, and see that at that amount of tokens you'd be lucky if it was 60% accurate or less; meaning 40% or more of the time it gives you a wrong answer.
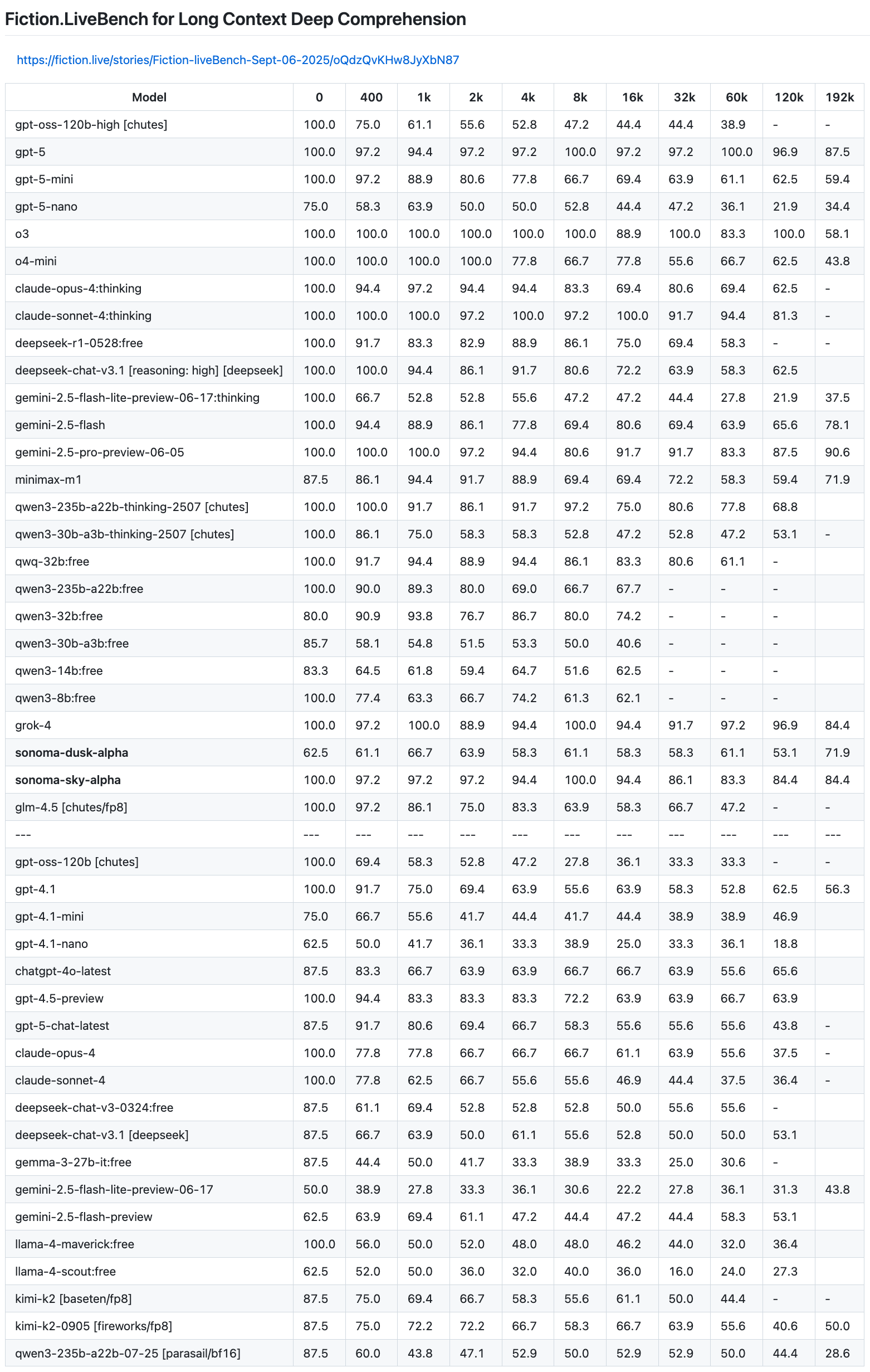
Moving down the scale, though, is a different story. At 16k tokens it could be 90% accurate or more; maybe even 100%, meaning it almost always gives you the right answer.
This defines your problem statement for you. If you want to rely on that data, then you need to ensure that you hand the LLM the answer it needs to respond to you in the range of tokens that gives 90-100% accuracy. If you have 300k tokens, that means you need to break your stuff up to fit in that much smaller chunks, like maybe 12-16k.
This makes RAG more of a software problem. Chunking your data, storing your data, and then having search mechanisms to find the right data to give to the LLM becomes the main factor. But that's all plain ol' development, with a bit of AI flavor added in.
You can't underestimate how important the surrounding tech on an LLM is. At the end of the day, that's going to define your experience as much or more than the model itself.