
Recursive Workflows- Offline Wikipedia Search in WilmerAI
On thing I've always wanted to do is have Wilmer workflows call themselves, so I can create a form of recursion within the workflows. This allows for a sort of semi-agentic behavior: repeated iterations on a problem with some breakout criteria.
Now that may sound like an agent, but that's not quite right. If you look under the hood of most agents, a lot of the agents' prompts, even across multiple steps, are going to be complex and deep; giving the LLM free reign in a step to decide a lot of things.
Not so in a workflow- every decision the LLM is presented is granular, specific, and the decision making process is so tightly controlled that it isn't given a lot of leeway to go off the rails or make mistakes. It CAN, but careful application of more steps can manage that.
I managed to pull it off today, with an offline Wikipedia deep research flow. I give it a topic to research, and it will work its way through wikipedia finding the answer.
For this, I've used 2 breakout criteria:
- The LLM can decide to call it quits at any time, and say "this is enough info"
- There is a maximum number of iterations
The overall workflow looks a bit like this:
- Step 1) Analyze my messages and come up with a research topic
- Step 2) Check to see if it has written down anything from a previous iteration that can be used here. If the notes from a previous run are good enough, it will use those and respond to the user.
- I do this in case I send followup questions. After the research is done, Wilmer will write the results to a text file. If I ask a followup question, it checks that text file first, as that's likely already got the info it needs. Then it doesnt need to hit wiki.
- Step 3) If the notes aren't good enough, it takes the analysis and generates keywords
- Step 4) It uses my Offline Wikipedia api, and pulls back the summaries endpoint to get 10 titles + first paragraphs. The LLM is presented with those, and picks the article it wants to use.
- Step 5) One of the LLMs, the best small model with a good context window, summarizes the article in relation to the research topic at hand
- The LLM also looks for any related topics within the article that may or may not be of value to search next
- Step 6) The LLM is given a chance to pick a new criteria within the research topic to search for, or to call it quits.
- Step 7) A ticker is iterated by one
- Step 8) Workflow sees if either we've hit max iterations, or the LLM wants to call it quits. If either is true, we're done.
- Step 9) Workflow calls itself, passing in what it's already searched and what it's already found, so it won't look at those again.
This works very similar to an agent, but far more tightly controlled. Where an agent is more autonomous, and you're relying heavily on the LLM to make certain decisions, in here the decision trees are narrower and every step is very finely managed, so that the LLM has very little freedom. This essentially means that it's far less autonomous than an agent, but also the quality is far easier to control.
Setting this workflow up took hours, compared to spinning an agent up in an hour or less, but the quality is fantastic. It's still a proof of concept, and I have a lot more work until I'm super happy with it, but seeing here it is right now is great.
Below is an example of a query I sent to an old model (probably llama 1?) running directly in Text-Gen-WebUI in Sept 2023 asking about Bumblebees; after that is the same query today, run in Wilmer.
Both are 100% offline; no internet at all. Just LLM and tooling progress.
Sept 2023
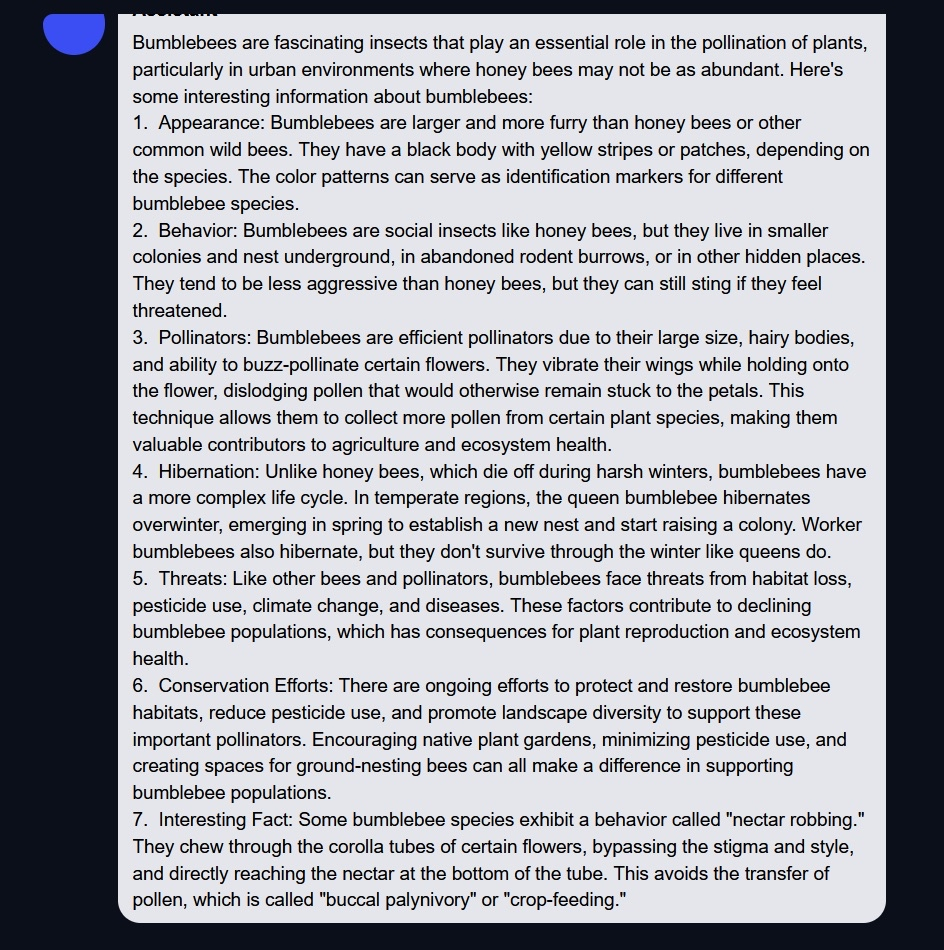
Sept 2025
